8.中心数据源
8.1.关于数据源
报表从数据源取数、填充是Supcan Report最重要的功能之一,数据源分二种:中心数据源和临时数据源。
所谓“中心数据源”是指可用的数据源全部都已经预先编排好了,客户编制报表时,只要获得中心数据源目录列表的URL,就能从中挑选本张报表需要的各种数据,例如制作销售统计表时,从数据源中心的数据目录树中挑选和销售有关的数据源即可。
采用中心数据源,报表制作者只要有数据目录的URL,就可以实现不需要程序员帮助的报表制作;对于程序员而言,只要把能提供的数据归并到中心数据目录即可,不必关心具体的报表制作过程,真正实现了数据与格式的分离。
所谓“临时数据源”是指每一个数据源的URL都需要程序员告诉最终的制表者,从哪里去获得数据,没有一个统一的数据发布途经,所以这只是临时的报表制作方案。当然如果对报表的自定义要求不高、报表数量不多的话,临时数据源也能实现和中心数据源同样的功能。此外“临时数据源”支持更多种类的数据格式。
“临时数据源”相对比较简单,您只要按最下面的附录.数据源实例做一遍,就应该对其有所了解,在此不再作分析。
8.2.基本协议
中心数据源协议核心是2个协议:目录协议和描述协议,这2种协议其实就是2种格式的XML。建设中心数据源的基础工作,主要就是维护这2种XML文件(或http响应)。
此外,还有根据需要可选的协议,比如单个数据源的描述协议、懒加载协议、搜索协议等。
8.2.1.数据源目录协议
中心数据源首先必须要有一个总的目录,这个目录好比就是电话号码本,里面记载了每个可用数据源的入口。
数据源目录是XML格式的,必须由程序员预先编排好,XML举例如下:
<?xml version="1.0" encoding="UTF-8"?">
<Catalog>
<Project text="业务数据" tip="货运数据">
<ds id="1001" descURL="data1.desc.xml" dataURL="data.xml">货运数据</ds>
</Project>
<Project text="财务数据" >
<ds id="2001" descURL="fin.xml" dataURL="serv1?para=1" tip="资产类科目余额">资产</ds>
<ds id="2002" descURL="fin.xml" dataURL="serv1?para=2" tip="负债类科目余额">负债</ds>
<ds id="2003" descURL="fin.xml" dataURL="serv1?para=3" tip="权益">权益</ds>
</Project>
<Project text="以往年度数据" lazyload="old1.aspx?nj=3">
</Project>
</Catalog>
协议说明如下:
1.该XML树、子树的级别无限制,树的元素命名也无限制,Supcan Report都能够正确地解析、显示出来;
2.上例中红色部分元素名必须书写正确,黑色部分为可选;
3.上述XML中,带id的行表示某个具体的数据源,其id必须唯一,id可以为英文字母、数字、下划线组合,但不得包含斜杠。该目录树一旦正式发布、投入使用,id不得轻易修改,因为id会被保存在引用了该数据源的报表的XML文件中;
4.descURL表示描述该数据源的XML的URL,数据源描述协议在下面有介绍。该URL可以是绝对URL,也可以是相对URL(相对于中心数据源目录XML),例子中就是相对URL;
5.dataURL表示该数据源最终数据的URL,对于JavaEE开发者而言,这就象是一个Servlet。该URL可以是绝对URL,也可以是相对URL(相对于中心数据源目录XML),例子中就是相对URL;
6.LazyLoad表示懒加载,鼠标首次点击让它展开时动态从后端加载子孙;
7.tip表示内容帮助,即鼠标滑过该数据源时会出现的略为详细的黄色说明条;
8.黑色加粗部分(即XML的Text)为数据源的含义正文,制表者在挑选数据源时看到的就是这些文字,通常要求简短而含义准确;
8.2.2.数据源描述协议
上述目录中,每条都有一个名为 "descURL" 的属性,这个 descURL 就是指向该数据源的详细描述的XML文本,这就是数据源的描述协议.
该XML描述了各个数据列的属性,描述协议举例如下:
<?xml version="1.0" encoding="UTF-8"?">
<cols>
<col name="orderID" datatype="int" hyperLink="conID">订单号</col>
<col name="orderDate" datatype="date">订单日期</col>
<col name="conID">合同号</col>
</cols>
协议说明如下:
1.元素名必须书写正确;
2.datatype可以是string、int、double、date、datetime,默认是string(即datatype="string"可以忽略);
3.hyperLink表示该列允许被超链接,指向超链接的列;
8.3.参数协议
采用中心数据源后,制表者会倍感轻松,但是也会面临一个问题:参数问题,例如获取销售数据,通常会有时间段的要求,如何获得有指定时间、地点或其它查询条件的数据,通常都采用查询“参数”来解决。
以上述中心数据源目录XML为例,带参数的数据源目录格式举例如下:
<?xml version="1.0" encoding="UTF-8"?">
<Project name="业务数据" tip="货运数据">
...
<ds id="11" para1="月份" para2="组织号" dataURL="data.serv?month=@para1&org=@para2" descURL="data1.desc.xml">货运数据</ds>
<ds id="12" para1="搜索串" dataURL="data.serv?search=@para1" descURL="data1.desc.xml" isPost="EncodeURIComponent">货运数据</ds>
...
</Project>
这样就实现了带参数的查询,该部分协议规定如下:
1.预先定义的参数,元素名为para1、para2、...,序号从1开始,其内容为参数的含义;
2.若预先定义了参数,dataURL中须有@para1、@para2之类的宏,最终Supcan Report会根据真实的参数拼装出真正的URL,并向服务器发送GET请求.
这是数据源目录中的参数预定义规则,在具体的制表过程中,参数可以通过如下途经设置:
1.直接在公式中输入,例如"=datarow('ds1', 1, '001')";
2.将参数指向某个单元格,例如:"=datarow('ds1', C6, '001')",其中C6是指C6单元格,只要在C6单元格输入了月份数据,数据会立即刷新;
3.在上例中,C6单元格可以制作成下拉,将月份字典表赋予给此单元,最终用户只要从下拉中选择月份,数据也能刷新;
4.在页面中通过js调用Supcan Report的SetParas()函数,直接设置查询条件;
5.isPost 可以是 false / true / encodeURIComponent,默认是false(即 GET);否则将dataURL中问号(?)后面的内容拆分出来安置在 http Body 中;而"encodeURIComponent"则表示参数内容预先做encodeURIComponent处理,和ajax post处理方式一致;
8.4.单个数据源描述协议
“单个数据源描述协议”是一个可选的协议, 服务端返回的XML结构举例如下:
<?xml version="1.0" encoding="UTF-8"?">
<cols dataURL="data.serv?month=@para1&org=@para2" para1="月份" para2="组织号" >
<col name="orderID" datatype="int" hyperLink="conID">订单号</col>
<col name="orderDate" datatype="date">订单日期</col>
<col name="conID">合同号</col>
</cols>
它相当于将dataURL、para参数和列信息统统写在一起了。
该协议的使用场景如下:
假如某张报表已经使用了中心数据源,假设其数据源 id 为 "1001", 当硕正报表打开这张报表后,它会在中心数据源目录URL的后面增加参数“serviceId=1001”,以这个URL访问服务器。其实它是试图绕过目录服务,单独取得这个数据源的结构信息.
假如中心数据源目录的URL为 "../serv/centercat.aspx", 那么单独获取的URL为 "../serv/centercat.aspx?serviceId=1001";
您的后端程序遇到这种请求,有如下2种处理方案:
1.按照本“单个数据源描述协议”,返回该数据源的结构;
2.不理会本协议,直接返回整个数据源目录,相当于是无视“serviceId=1001”这个参数;
不管您返回上述哪种XML,硕正报表都能正确辨认,达到取得该数据源的结构的目的。
在您的中心数据源目录比较庞大、访问获取时比较耗时的情况下,实现“单个数据源描述协议”能明显提升报表的性能。
8.5.懒加载协议
如果中心数据源目录中条目增多,假如达到数千条,这个XML数据的下载会很慢,为此,我们的目录协议还支持另一种XML格式:采用平面的结果集格式,以 "pid" 属性指定树的上层 id,例如:
<?xml version="1.0" encoding="UTF-8"?">
<Catalog treeformat="bypid">
<ds id="1" text="业务数据" tip="货运数据"/>
<ds id="1001" pid="1" descURL="data1.desc.xml" dataURL="data.xml" text="货运数据"/>
<ds id="2" text="财务数据" />
<ds id="2001" pid="2" descURL="fin.xml" dataURL="serv1?para=1" text="资产"/>
<ds id"2002" pid="2" descURL="fin.xml" dataURL="serv1?para=2" text="负债"/>
<ds id="3" text="以往年度数据" lazyload="old1.aspx?nj=3"/>
</Catalog>
该协议须注意:
1.顶部的<Catalog treeformat="bypid">就表示告诉硕正数据源管理器,目前使用的是byPid格式;
2.第8行的 LazyLoad 属性表示该行是树杈,鼠标点击展开时,会动态从这个URL加载其子孙的;
3.子孙的XML格式也应该和这个XML相似.
如果您准备启用LazyLoad模式,那么您必须同时也实现前述的“单个数据源描述协议”。
8.6.搜索协议
和上述懒加载的情形相似,如果中心数据源编目繁多,为了快速搜索到所需的数据源,还需要补充一个搜索协议。
当实例创建参数增加:DSCenterDialogHeader="search" 时,中心数据源对话框显示如下:
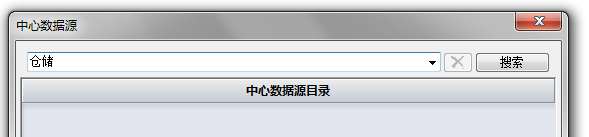 这就需要在硕正控件和后端服务之间设定一个协议,协议很简单:在中心数据源URL后增加search参数,假如中心数据源目录的URL是:
这就需要在硕正控件和后端服务之间设定一个协议,协议很简单:在中心数据源URL后增加search参数,假如中心数据源目录的URL是:
http://loaclhost/datacenter.aspx
那么数据源搜索的URL就是(假如搜索内容是 "仓储"):
http://loaclhost/datacenter.aspx?search=%e4%bb%93%e5%82%a8
其中"%e4%bb%93%e5%82%a8"是中文"仓储"的UTF-8编码.
此外,后端服务也同样需要实现数据源描述服务,即懒加载协议中的 serviceId=ID号 的服务。
8.7.其它说明
1.一张报表中可以有多个数据源,允许中心数据源、临时数据源混合使用;
2.一张报表只能有一个中心数据源目录URL,但是可以使用多个属于该中心数据源的具体数据源;
3.中心数据源的XML协议中,如果需要用到中英文对照,应该以竖线("|")分隔中英文,例如tip="合同号|Contact ID";
4.中心数据源具体的数据的格式只支持XML、JSON;
5.可以在页面js中调用SetSource(),预先设置中心数据源的URL;
6.上述XML中的元素名对大小写不敏感;